Challenge and study: Process Discovery Contest 2020 (PDC 2020)
ICPM challenge and studyPresented by Eric Verbeek
 The Process Discovery Contest (PDC) is the annual event that, since 2016, has been dedicated to the assessment of tools and techniques that discover business process models from event logs. To that end, synthetic data are used to have an objectified “proper” answer. Process discovery is turned into a classification task with a training set and a test set: the process model discovered from the training set is evaluated based on its ability to correctly decide which of the traces in the test set are fitting or not with the original (unknown) model. We talk about the PDC with a former contestant and now a newly acquired member of the organisation committee, Eric Verbeek.
The Process Discovery Contest (PDC) is the annual event that, since 2016, has been dedicated to the assessment of tools and techniques that discover business process models from event logs. To that end, synthetic data are used to have an objectified “proper” answer. Process discovery is turned into a classification task with a training set and a test set: the process model discovered from the training set is evaluated based on its ability to correctly decide which of the traces in the test set are fitting or not with the original (unknown) model. We talk about the PDC with a former contestant and now a newly acquired member of the organisation committee, Eric Verbeek.
Eric, tell us a bit about yourself and your research institute.
My name is Eric Verbeek, and I work at Eindhoven University of Technology (TU/e), which is one of four technical universities in The Netherlands. I've been working at TU/e for almost 30 years now as a scientific engineer, which is like an assistant professor but with “education” replaced by “support”. For the first ten years, I’ve worked at the Department of Mathematics and Computer Science, mostly on ExSpect (a modelling tool for coloured Petri nets, see www.exspect.com) and Woflan (a verification tool for sound workflow nets, see www.win.tue.nl/woflan). For the following six years, I’ve worked at the Department of Industrial Engineering, where I defended my PhD thesis on the verification of workflow nets. Meanwhile, the process mining field had started. I was there but only started working on our process mining tool ProM (www.promtools.org) later on. During the last fourteen years, I’ve worked again at the Department of Mathematics and Computer Science, with ProM as my main dish. My ingredients to this dish include the framework (the ‘plate’, if you like), the transition system miner, the decomposed discovery and replay, and, of late, the log skeletons.
What is your history with the process discovery contests?
When the first process discovery contest was started in 2016, I decided to contribute using a collection of (decomposed) discovery algorithms. The idea was quite simple: Some discovery algorithms guarantee perfect fitness, hence the model they return can correctly replay all the traces of the original event log (no false negatives). False positives (traces that are accepted by the process model, though they shouldn’t) were then avoided as much as possible by using a knock-out system: If the result of one of the discovery algorithms was a no-go, then the final classification was negative. This was implemented in the DrFurby (which is how "Dr. Verbeek" is sometimes pronounced in English) classifier plugin in ProM. To my amazement, this was the winning contribution.
Of course, the DrFurby classifier did not really return very usable models, hence in the process discovery contest of 2017 a jury was introduced to rank the usefulness of the discovered models by different contributions. To contribute to that contest, I started the log skeletons. The main idea behind this was that many of us seem to have a strong bias towards Petri-net-like models. As a result, I assumed that the contest logs would typically contain constructs that are hard to model (or discover) in a Petri net. Thus, I started with a new modelling formalism that would capture different properties than the properties as captured by Petri net. In the end, this resulted in the log skeleton formalism, which, as I learned later, was quite close to the declarative process modelling language of Declare. Although my contribution was the only one that classified all test traces correctly (after a lot of tuning, I must admit), I did not win the contest as the jury liked the interactively-discovered Petri nets from Alok Dixit over my automatically-but-tuned-discovered log skeleton models.
For the process discovery contest of 2019, I used again the log skeletons, which I had improved by then, but I would use them only to gain sufficient insights into the model to be able to create a Petri net manually. Although the 2019 logs were much tougher to tackle with the log skeletons than the 2017 logs, I succeeded in creating 10 Petri nets that in the end won the contest.
And now you are an organiser of the contest. What’s new in PDC 2020?
The winners of the process discovery contests of 2017 and 2019 “kept the expert in the loop”: Alok's discovery technique from 2017 requires an expert to make the necessary decisions along the way, and the conversion from the log skeletons to the Petri nets in 2019 requires an expert as well. But what about the automated discovery algorithms? What can we say about them? Obviously, they are not yet a match for an expert, but what should we do to close the gap between the algorithm and the expert? Which way to go to improve on these algorithms? To answer these questions, we should set up the contest a bit differently: Instead of asking the contributors to classify disclosed logs, we (the organizers!) should ask the contributors for their working discovery algorithms and do the classifications ourselves, on non-disclosed logs. This way, the contributors cannot tune their approach on the logs, as was done in earlier contests, and cannot take advantage of manual interventions. This, in the end, was the motivation for the current setup of the Process Discovery Contest 2020: The automated contest compares automated discovery algorithms, which shows the state-of-the-art among these algorithms, and the manual contest compares the algorithms to the experts, thus showing the gap we still need to bridge.
To implement this setup, this year, I joined the organization of the process discovery contest series. A configurable master model was created, from which event logs using different characteristics were generated: whether there are loops and of what complexity, whether there are optional tasks, duplicate tasks, noise, and so on. As the generation of the model and the logs requires precision and takes time, we created them all over the summer as that is a reasonably quiet period!
In the end, this has led to quite a number of event logs: 192 from which a model needs to be discovered, 192 that need to be classified by that discovered model, and 192 that contain the ground-truth classification. Every event log contains 1000 traces, of which at least 400 are positive and at least 400 are negative.
To score a discovery algorithm (we go a bit technical here), we use the F-score on the positive accuracy and the negative accuracy, where the positive/negative accuracy is the accuracy of the classification on the positive/negative (ground-truth) traces. We are thus looking for a balance between the correct classification of positive traces and the correct classification of negative traces. The discovery algorithm with the highest average score, wins the automated contest! Note that the automated contest has already started: You can submit your contribution today! And you can submit an updated version of your contribution tomorrow! Every submitted contribution counts.
After the automated contest has run, we will disclose the most complex log, that is, the one generated by setting all the characteristics I mentioned above to their maximum level. This will start the manual contest. The manual contest will run for about two weeks, during which the contestants can submit a classification for this one log. How the classification was created is irrelevant to us. If needed, a contestant may just classify every trace in the log manually. However, only the last submitted classification counts! The contestant with the best score wins the manual contest.
More details on the PDC 2020 can be found on its website: icpmconference.org/2020/process-discovery-contest
How do you see the future of the Process Discovery Contest?
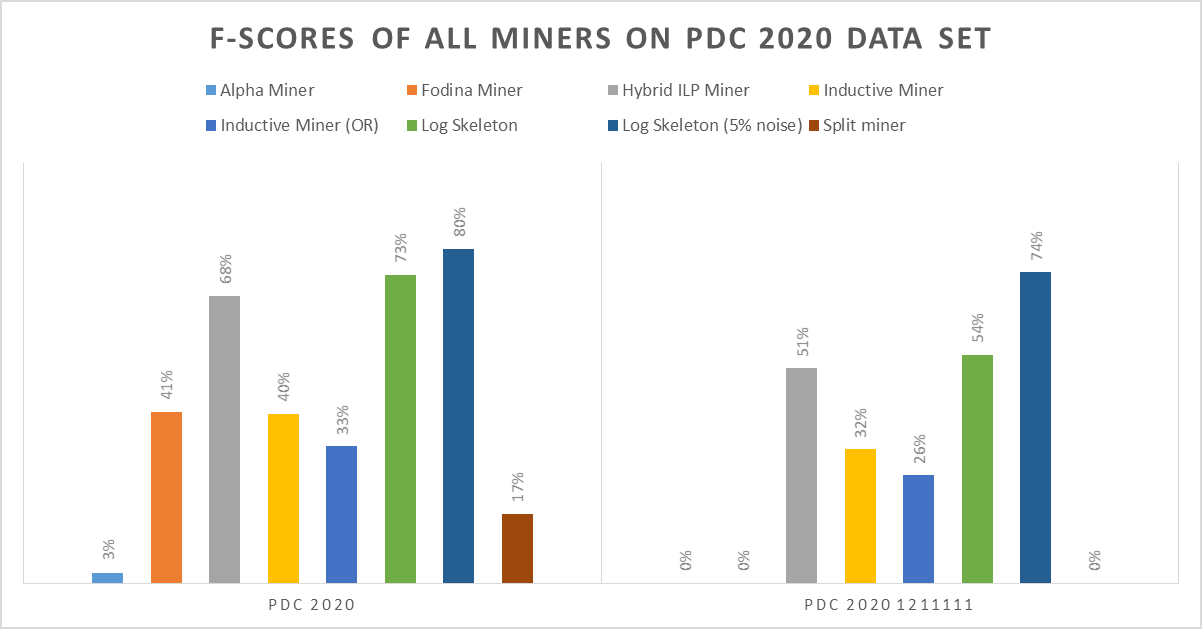
With the current setup of the contest, we (the organizers) can build a body of working discovery algorithms. To start this, we have implemented eight sample working discovery algorithms, including the Alpha Miner, the Fodina Miner, and the Log Skeleton (details on these and the other implementations can be found on the website of the PDC 2020). Notice that those implementations are not contributions to the contest! If the authors of these miners want to contribute, they should submit them. As a result, we will be able to score these discovery algorithms in the future on new data sets as well, like for a next contest, and see whether new discovery algorithms have advanced over the old ones.
By adding the data set of every future process discovery contest, and by adding other interesting data sets as well, we can also build a body of data sets that we can use to test process discovery algorithms. Next to the PDC 2020 data set, we have already included a number of existing data sets in this body: PDC 2016, PDC 2017, PDC 2019, and aXfYnZ. The three PDC data sets are from the previous editions of the process discovery contest; the aXfNyZ data set was created by Laura Maruster, who was the first PhD candidate to defend a thesis on process mining, for as far as I know!
Together with the body of discovery algorithms, this body of data sets can provide a fair view on the current state of the field of process discovery algorithms. As an example, the figure below depicts the results of the eight sample discovery algorithms on the PDC 2020 data set. This shows that the Log Skeleton with 5% noise scores the best on the PDC 2020 data set with a score of 80%, and that experts need to score at least 75% to outperform this discovery algorithm. It also shows that on the PDC 2020 data set, the Hybrid ILP Miner is the Petri-net-based discovery algorithm that scores best. Other results can be found as well on the website of the PDC 2020.
- Academic stories: Hajo Reijers
- Developers’ point: Lana Labs
- Exploring newland: From Process Mining to Automated Process Improvement
- End-user’s corner: Dominic Giss
- Challenge and study: Process Discovery Contest 2020 (PDC 2020)
- Conference room: Business Process Management (BPM 2020)
- ICPM 2020: get ready!
- This article has been updated on September 8 2020, 07:12.
- Presented by Eric Verbeek
